
PyTorch Lightning Basics

I am a Software Engineer, with a passion for building cool stuff. I love to learn new languages in my spare time. I also make music as a hobby.
Introduction
PyTorch Lightning is a framework built on top of the PyTorch deep learning framework for ease of use, think of it as a Keras-like API for the PyTorch framework. I have planned to write this series of articles from my own experience in using it for my research purposes. These articles assume that you have a good grasp of Deep Learning and PyTorch.
Installation
To install PyTorch Lightning use pip install pytorch-lightning.
Concepts
First, we will go over some of the important concepts in PyTorch Lightning so that it would be easier to work with them later. The PyTorch Lightning framework has been able to capture most of the requirements of people who are creating deep learning models. At the end of this article, we will be going through a mock dataset to show the full framework in action.
Model
A model is the neural network model that we need to learn some particular task. For that, we have the pytorch_lightning.LightningModule is similar to the PyTorch module, nn.Module.
The scaffold for a basic model is as follows.
import torch
import pytorch_lightning as pl
class MyModel(pl.LightningModule):
def __init__(self):
super().__init__()
def forward(self, x):
## the forward pass
def configure_optimizers(self):
## configure the optimizer that is used by the model
# optimizer = torch.optim.Adam(self.parameters(), lr=self.lr)
# return optimizer
def training_step(self, batch, batch_idx):
## the training step
def validation_step(self, batch, batch_idx):
## the validation step
def test_step(self, batch, batch_idx):
## the test step
The forward method is similar to the one in PyTorch it is called whenever the input is needed to be fed into the network for a forward pass.
Likewise each of the methods training_step, validation_step and test_step is called when the model is in training, validation and test phases respectively.
Dataset
To load data into the model we have to create a class that extends from the PyTorch Dataset class. Even though the PyTorch Lightning framework has its own LightningDataModule class it in turn depends on the PyTorch Dataset class.
Below is a way to handle data pipelining in PyTorch Lightning.
from torch.utils.data import Dataset
import pandas as pd
class MyDataset(Dataset):
def __init__(self, dataset_type="train"):
if dataset_type == "train":
## load the train dataset
self.df = ...
elif dataset_type == "validation":
self.df = ...
elif dataset_type == "test":
self.df = ...
def get_features(self, index):
## extract the needed features
X = ...
return X
def get_label(self, index):
## extract the needed label data
y = ...
return y
def __len__(self):
return len(self.df)
def __getitem__(self, index):
X = self.get_features(index)
y = self.get_label(index)
return (X, y)
The __getitem__ method is important here because by using this we can mould the data however we want it to be presented to the model.
Here, you can load the data any way you like but the flow would be similar. In this case, we have used dataset_type to differentiate between the types of data that we need, but you can use a method that is best for your particular need.
DataLoader
For the dataset to load the data in efficiently PyTorch has the DataLoader class which loads the data in batches and also uses concurrency to speed up the process.
from torch.utils.data import DataLoader
dataset = MyDataset()
dataloader = DataLoader(
dataset,
batch_size=32, # number of samples to load at a time
num_workers=4 # number of threads (= number of processors)
)
Trainer
The Trainer, as the name implies is the class responsible for the training and evaluation of the models that you create. It has a myriad of options that you can go through in the official documentation. For this article, we will go through a subset of these options that are critical for operating with it.
import pytorch_lightning as pl
from torch.utils.data import DataLoader
# create the model
model = MyModel()
# create the datasets
train_dataset = MyDataset(dataset_type="train")
validation_dataset = MyDataset(dataset_type="validation")
# create the dataloaders
train_dataloader = DataLoader(train_dataset, batch_size=32, num_workers=4)
validation_dataloader = DataLoader(validation_dataset, batch_size=32, num_workers=4)
# create the trainer
trainer = pl.Trainer(
gpus=1, # number of gpus to use -1 to use all
max_epochs=10 # maximum number of epochs the trainer will execute
)
trainer.fit(
model,
train_dataloader=train_dataloader,
val_dataloaders=validation_dataloader
)
Trainer Constructor Arguements
gpus- Specifies how many GPUs to use for the training purpose, by default it uses none.max_epochs- Specifies the maximum number of epochs (how many times the dataset is shown to the model).
fit Method Arguments
train_dataloader- Specify the data loader which is used by the trainer.val_dataloaders- This can be either a list of data loaders or a single data loader, which is then used by the trainer to evaluate the model.
A Simple Example
To make use of the stuff that we have gone through, we will be making a simple model that can identify data points that belong to 4 classes. These data points will be created using sklearn.
1. Creating the Dataset
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
classes = 4
n_samples = 1000
(X, y) = make_blobs(n_samples=n_samples, n_features=2, centers=classes, cluster_std=2.5, center_box=(-10, 10) , random_state=42)
## Splitting the datasets
(X_train, X_test, y_train, y_test) = train_test_split(X, y, test_size=0.2, random_state=42)
(X_train, X_validation, y_train, y_validation) = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
colors = ['red', 'green', 'blue', 'black', 'purple']
cdict = dict(map(lambda x: (x, colors[x]), range(0, classes)))
fig, ax = plt.subplots()
for g in np.unique(y):
ix = np.where(y == g)
ax.scatter(X[ix, 0], X[ix, 1], c = cdict[g], label = g)
ax.plot
ax.legend()
plt.show()
Below is the clustering of points that we are trying to fit a model to.
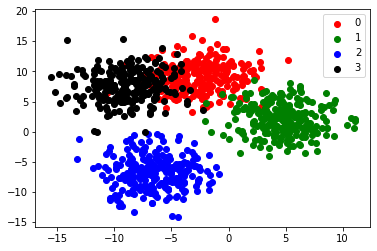
2. Create a Custom Dataset
import torch
from torch.utils.data import Dataset, DataLoader
class MyCustomDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
self.count = X.shape[0]
def __len__(self):
return self.count
def __getitem__(self, index):
X = self.X[index]
y = self.y[index]
return (torch.tensor(X, dtype=torch.float32), y)
ds_train = MyCustomDataset(X_train, y_train)
ds_validation = MyCustomDataset(X_validation, y_validation)
ds_test = MyCustomDataset(X_test, y_test)
dl_train = DataLoader(ds_train, batch_size=16, num_workers=2)
dl_validation = DataLoader(ds_validation, batch_size=16, num_workers=2)
dl_test = DataLoader(ds_test, batch_size=16, num_workers=2)
3. Create the Custom Model
## create the model class
import pytorch_lightning as pl
import torch
from torch import nn
from torch.nn import functional as F
class MyModel(pl.LightningModule):
def __init__(self):
super().__init__()
## make the model
self.classifier = nn.Sequential(
nn.Linear(in_features=2, out_features=4),
nn.ReLU(),
nn.Linear(in_features=4, out_features=4)
)
## use cross entropy loss for categorical problems
self.loss = F.cross_entropy
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=0.01)
return optimizer
def forward(self, x):
x = self.classifier(x)
return x
def training_step(self, batch, batch_idx):
x, y = batch
y_logit = self(x)
loss = self.loss(y_logit, y)
pred = F.softmax(y_logit, dim=1)
self.log('train/loss', loss, prog_bar=True, on_step=False, on_epoch=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_logit = self(x)
loss = self.loss(y_logit, y)
pred = F.softmax(y_logit, dim=1)
self.log("val/loss", loss, prog_bar=True)
def test_step(self, batch, batch_idx):
x, y = batch
y_logit = self(x)
loss = self.loss(y_logit, y)
pred = F.softmax(y_logit, dim=1)
self.log("test/loss", loss)
4. Train the Model
trainer = pl.Trainer(
max_epochs=10
)
model = MyModel()
trainer.fit(
model,
train_dataloader=dl_train,
val_dataloaders=dl_validation
)
With the above code we execute the training_step and validation_step of the model to train and also validate the model.
5. Test the Model
After training the model, we can use the test set to check the model performance with unseen data.
trainer.test(
model,
test_dataloaders=dl_test
)
The output of training and testing of the model is as follows.
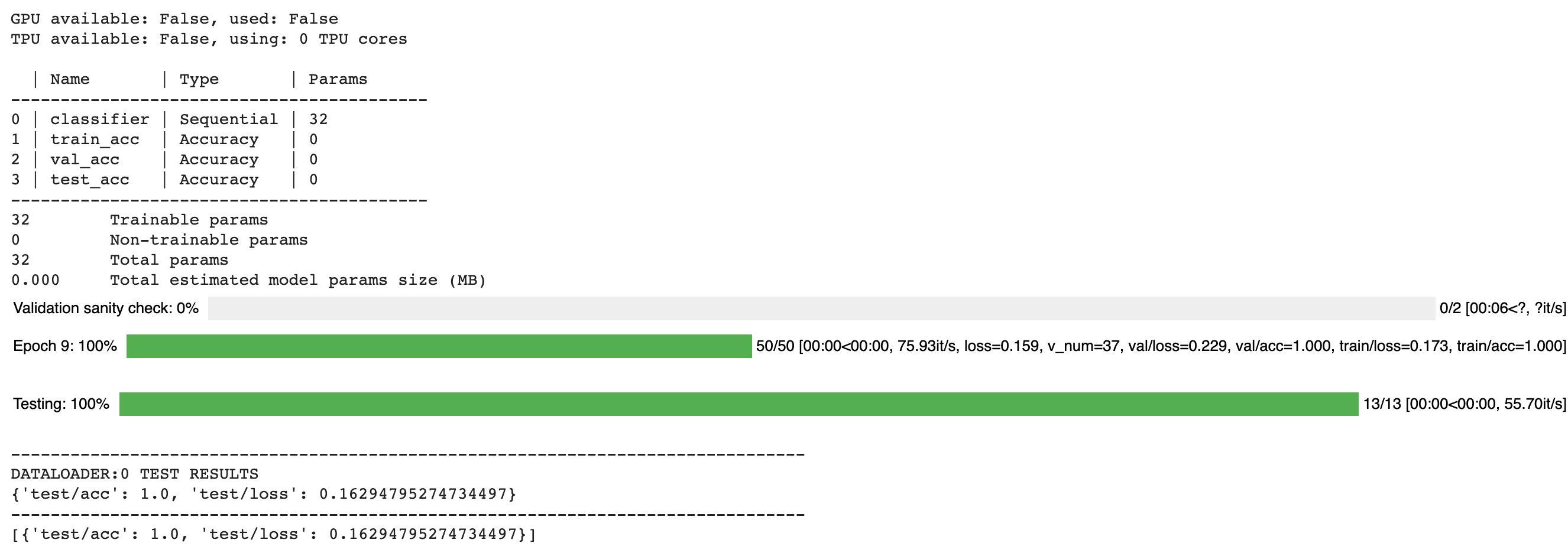
6. Save the Checkpoint
We will manually save the model for now, but the Trainer has more advanced options that allow us to automate the saving of models. You can check the documentation for more details.
trainer.save_checkpoint("example.ckpt")
Conclusion
In this article, we have gone through each of the main steps that are necessary for using the PyTorch Lightning framework. The framework is a wonderful addition on top of the PyTorch framework. I will be posting more topics regarding PyTorch Lightning and Deep Learning in general.



